Literate Home Assistant Configuration
Introduction
Home Assistant is a leading open-source platform for home automation. My first experiments with it date back to 2022, and my evolution path since then might have been, I guess, quite typical. I started small but kept adding new smart devices, automations and all that stuff. Before long I realized that my configuration has become complex and unwieldy. I found it rather difficult to work with definitions scattered across the front-end UI pages and/or YAML files, despite all the great improvements to the user interface that have been introduced recently.
I spent some time considering my requirements and came up with the following list:
- Source code management applied to all YAML definitions, perhaps except trivial ones.
- Related definitions across all categories, such as automations, scripts or template sensors, should be kept together.
- It should be possible to document definitions well beyond what’s reasonable to have as object descriptions.
- I want to keep an archive of scripts, template sensors etc. that needn’t be necessarily configured in my Home Assistant server.
As it turned out, with the toolset that I’ve been using for decades, especially Git, Emacs and Org mode, it was possible to achieve the above goals pretty easily. I realize that my solution, which I call literate configuration, isn’t for everybody but, after two years of almost daily usage, I must say that it works almost perfectly and has already saved me a lot of time and trouble.
Code blocks and YAML in Emacs
One of the less frequently used features of Org mode is the ability to intersperse text with code blocks enclosed in #+begin_src <language> and #+end_src, where <language> identifies the programming language in which the code block is written. If such a block is opened for editing (the default key combination for this is Ctrl-C '), Emacs activates the editing mode that’s available for the given language, and then inserts the edited code back to the Org source file.
Even though Org supports all common languages, YAML isn’t among them – maybe because it really isn’t a programming language. It was however quite easy to implement support for YAML code blocks by modifying the provided Emacs Lisp template. The resulting module ob-yaml.el is available on GitHub and can be loaded in Emacs as usual.
Literate programming
The term literate programming was coined by Donald Knuth in 1984 as a way for developing computer programs as pieces of literature that humans can easily read and enjoy. He then used this programming method for developing the TeX typesetting system that many of us still use. The Org mode uses the noweb implementation of literate programming. Two of its features are important for our purposes:
- Designated code blocks can be “tangled“ – extracted from the Org source and pasted sequentially into one or more files.
- A named code block can be referred to from other code blocks by using its name enclosed in
<<and>>. The code from the referred block is then inserted in the referring block when the latter is tangled.
The former approach is simpler and useful for putting together chunks that are at the top level of YAML hierarchy, for example
#+begin_src yaml :tangle customizations.yaml
sensor.ecovolter_total_energy:
device_class: energy
#+end_srcChunks with the same value of the :tangle parameter are collected, in the order as they appear in the source Org file, in the specified file (customizations.yaml for the example above).
YAML chunks to be placed somewhere deeper in the hierarchy can be handled using the second approach (noweb references). One has to write a skeleton configuration file, and then refer to individual chunks from it. For instance, the configuration file for RESTful integration looks like this (abridged):
#+begin_src yaml :tangle rest.yaml
- resource: !secret ecovolter_get_url
scan_interval: 5
verify_ssl: true
headers:
X-API-KEY: !secret ecovolter_api_key
sensor:
<<sensor.ecovolter_boost_current>>
<<sensor.ecovolter_target_current>>
<<sensor.ecovolter_boost_time>>
...
binary_sensor:
<<binary_sensor.ecovolter_single_phase>>
<<binary_sensor.ecovolter_charging_enabled>>
...
#+end_srcYAML definitions of all sensors or binary sensors may appear anywhere in the source Org file. Each has to be designated by the same name that was used in the corresponding noweb reference (between the chevrons << and >>). Here is an example:
#+NAME: sensor.ecovolter_target_current
#+begin_src yaml
- name: "EcoVolter target current"
unique_id: "ccbfbac7-8eb3-4bb9-9951-4d41acfd5a1e"
icon: "mdi:car-electric"
value_template: "{{ value_json.targetCurrent }}"
unit_of_measurement: "A"
#+end_srcWhen tangling the output YAML file, Emacs observes the indentation level of the noweb reference and indents the included chunk accordingly. The chunk itself thus needn’t be indented within its code block, which is very handy.
The noweb references may use any names, as long as they are unique, but I found it very convenient to use complete HA entity names because one can then immediately look up the entity in the graphical UI.
Deployment
It’s nice to be able to generate all YAML configuration files from a single Org source, but by itself it isn’t sufficient. In order to make this system practical, I had to find a way for automating the process of deploying the generated files on my Home Assistant server. After some experimenting I ended up with the procedure described below. There can certainly be other ways of achieving the same but here I was able to leverage functionality already available in Git and Home Assistant.
The procedure consists of the following steps:
- Edit the source Org file Emacs.
- Review, stage and commit the changes to Git.
- Push the new commit(s) to a remote repository on my home network server.
- Activate the new configuration on the Home Assistant server, usually via quick reload.
Most of of the underlying magic happens in step 3: the remote Git repository uses a pre-receive hook that does the following:
- check out the working tree on the remote server
- use Emacs in the batch mode on it to tangle all YAML configuration files (still inside the working tree)
- use rsync to synchronize modified YAML files with the
configdirectory on my HA server.
Below is a transcript of the git push operation that also contains terminal output of the hook script (prefixed with remote:). A useful detail in the output of rsync is the list of YAML configuration files that have been updated – here it is just automations.yaml.
$ git push
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Delta compression using up to 8 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 343 bytes | 343.00 KiB/s, done.
Total 3 (delta 2), reused 0 (delta 0), pack-reused 0
remote: Already on 'master'
remote: Loading /etc/emacs/site-start.d/00debian.el (source)...
remote: Loading /etc/emacs/site-start.d/50autoconf.el (source)...
remote: Tangled 36 code blocks from ll-ha-config.org
remote: sending incremental file list
remote: automations.yaml
remote:
remote: sent 45,826 bytes received 47 bytes 30,582.00 bytes/sec
remote: total size is 127,670 speedup is 2.78
To trail.lhotka.name:Depot/hazard
9f0eccf..8294a02 master -> masterThe hook script looks like this:
WDIR="/home/ha/literate-ha"
ORG="ll-ha-config.org"
read oldref newref refname
branch=$(basename $refname)
rm -rf $WDIR/*
git --work-tree="$WDIR" checkout $branch -f
cd $WDIR
emacs --batch --eval "
(progn
(setq org-id-track-globally nil)
(find-file \"$ORG\")
(org-babel-tangle))"
rsync -crv --delete \
--exclude 'ui_lovelace_minimalist/custom_*' \
--exclude 'blueprints/automation/homeassistant' \
--exclude 'blueprints/script/homeassistant' \
--exclude 'blueprints/template/homeassistant' \
--exclude 'esphome/trash' \
--exclude 'esphome/.gitignore' \
*.yaml esphome ui_lovelace_minimalist \
custom_templates blueprints /mnt/haCode organization
An outline of my HA literate configuration with all sections folded (collapsed) can be seen in Figure 1 (a):
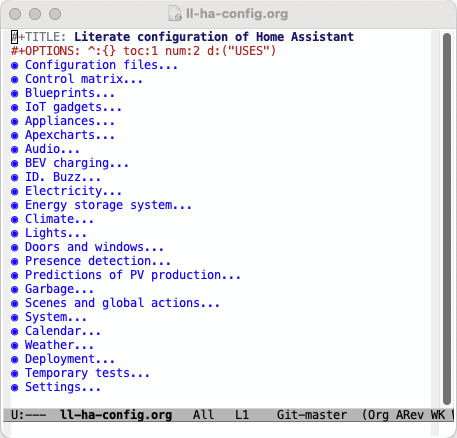
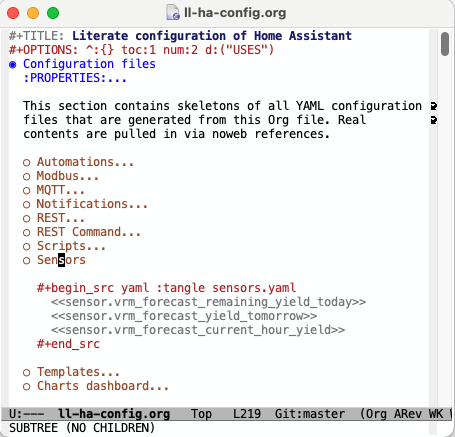
The first section (shown partially unfolded in Figure 1 (b)) contains skeletons of most YAML configuration files that are generated from the master file. Their names are specified in the :tangle directive in the header of each code block. Most of the remaining sections then contain literate configuration organized by particular topics such as electricity costs (see Figure 2) or BEV charging.
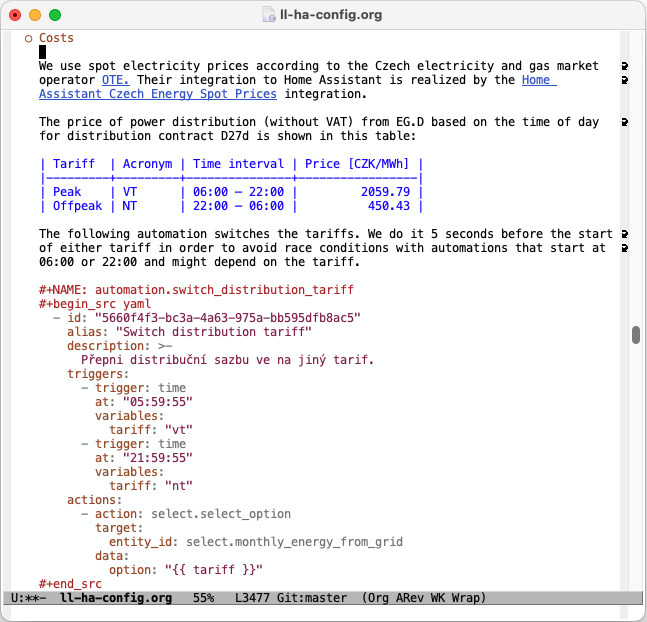
When searching for an existing definition of an automation, script, template sensor etc., I can either
look it up in the corresponding skeleton file by name and then easily navigate to its YAML definition using the command
org-babel-goto-named-src-block(bound by default toCtrl-C Ctrl-v g), orbrowse the appropriate section and find it in the text.
The IoT gadgets section contains descriptions of all smart devices (plugs, buttons, NFC tags etc.) that are in use. Other sections refer to them where needed, for example to document that an appliance is connected to or controlled by the device.
Literate configuration and the standard UI
The standard web user interface of Home Assistant has been steadily improving and has become truly indispensable for certain kinds of tasks. Fortunately, dealing with configuration in the literate style (mostly) doesn’t mean that one has to avoid the standard UI as a configuration tool. On the contrary, both configuration approaches can be used in a synergy, one just has to be a little careful.
For example, when creating a new automation, I often start with the web UI and take advantage of autocompletion and other nice features of the web forms and widgets. After saving it, I copy and paste it to a code block in Emacs, make additional edits if necessary and finally commit and push the result to the Git repository. Similarly, it is quite convenient to develop a Jinja2 template in the web UI and then copy the final result to a code block in the Org file.
When it comes to custom dashboards, I originally started with UI-Lovelace-Minimalist and had all its configuration in my Org file. It helped me a lot to keep the set of dashboards organized but it was still quite tedious to manage the entire user interface in source code. Not long ago I realized that I could no more ignore the vast improvements in the standard (Lovelace) dashboards and decided to migrate. Regrettably, there is this strict dichotomy of UI versus YAML modes for dashboard configuration. I chose the former because it is very convenient to lay out and update the dashboards via the graphical interface. Nonetheless, there are still situations where it would be more efficient to work with YAML code and literate configuration. In particular, I have separate dashboards for desktops, mobile devices and wall panels, so I quite often need to reuse same cards in different places. I can either configure them repeatedly via the UI, which is a drudgery for all but trivial cards, or copy and paste YAML code between web forms, which is difficult and error prone. I would thus very much appreciate to be able to work with YAML code and via UI interchangeably, as it is possible for scripts and automations.
I do keep one dashboard in the YAML mode and work with it in the literate configuration style. It contains my collection of ApexCharts. The reason for this exception is twofold: first, ApexCharts have to be configured completely in YAML anyway, and, second, it is much easier to copy fragments of YAML code in Emacs (with adjusted indentation, if necessary) and paste them to other dashboards in UI mode.
Other goodies
Apart from the main features of Org and YAML modes that were described above, there are a few other useful functions.
First, Emacs can help with generating unique IDs that are very important in Home Assistant. Whilst they aren’t required everywhere, I soon learnt to put them where possible (automations, template sensors etc.). It may seem logical to use descriptive strings as unique IDs, but as soon as one needs to change the underlying entity the previously assigned ID could become confusing if it no more reflects reality. Hence, a better practice is to use opaque strings, as Home Assistant does internally. Emacs can generate them with the uuidgen function, which I have bound to Ctrl-+ for easy access.
Org mode also offers extensive possibilities for exporting the source text in various formats. The HTML export might be useful for publishing a literate configuration (or parts thereof) as a web page. I personally don’t see much reason to publish my configuration in its entirety, as long as the resulting HTML doesn’t support collapsible sections in the same way as the Org source does. I occassionally use HTML export for publishing fragments dealing with specific topics. It is also very useful that GitHub now supports the Org mode syntax directly, so one can view nicely rendered literate configuration files out of the box. An example is here.
Conclusions
The workflow for literate configuration that I described in the previous sections makes me feel confident that I am in control of my Home Assistant configuration. I can easily return to any topic even after a long break, refresh my understanding of how the relevant entities, automations and scripts are supposed to work together, and update or extend the configuration.
But – is this system for everybody? Objectively, it isn’t. For one, if you aren’t an Emacs user yet, it might not be very effective to learn the editor and the Org mode just for the sake of configuring Home Assistant. On the other hand, I do think that the Org mode is so powerful and useful that it is a reason good enough for starting with Emacs in the first place.
Second, the literate approach probably isn’t for someone who wants to get things done quickly. A literate configuration needn’t necessarily be a piece of art but it still requires certain extra effort and a bit of careful planning. For complex configurations, though, this overhead will pay off in a long term.
And finally, I think beginners may be better off using the Home Assistant’s native UI that is more intuitive and provides contextual help in many places. It is possible to migrate configuration to the literate style at any later time.